Dynamic Mapping of Columns Getting Groovy with Talend at Runtime
Sometimes you have a data source where you know the fields but you do not know their order. Or you may only need a subset of the fields provided. If the input schema and the output schema are known in advance you might use the tFilterColumn component. Or you could use tMap. But both of those approaches require recompiling the job and then redeploying.
Sometimes we want more dynamic behavior and we would like to drive this behavior in a data driven manner based on configuration files provided at runtime.
If we do not know the schema in advance there is no obvious and simple way in Talend to have the end user (not the developer) supply the column mapping via a data centric API. There are a few sample out there in the community, but they are somewhat hard to use. This post provides an example of using tGroovy to provide this functionality in a simple, encapsulated manner that is flexible and extensible. A sample job is included.
This approach takes advantage of the fact that Groovy offers an API for the underlying bean properties. In Java you may have a class MyClass with a property myProperty. In Java the accessors on myProperty are part of your code, and they cannot be specified as dynamic arguments at runtime. The only way to access them is as Java fields (if they are public) or with accessor methods such as getMyProperty at compile time. In contrast, Groovy allows you to access properties with accessor methods, with fields, and with a dictionary style interface much like Javascript, e.g. myClassObj[“myProperty”]. In this example the string “myProperty” is static, but it could of course be a variable.
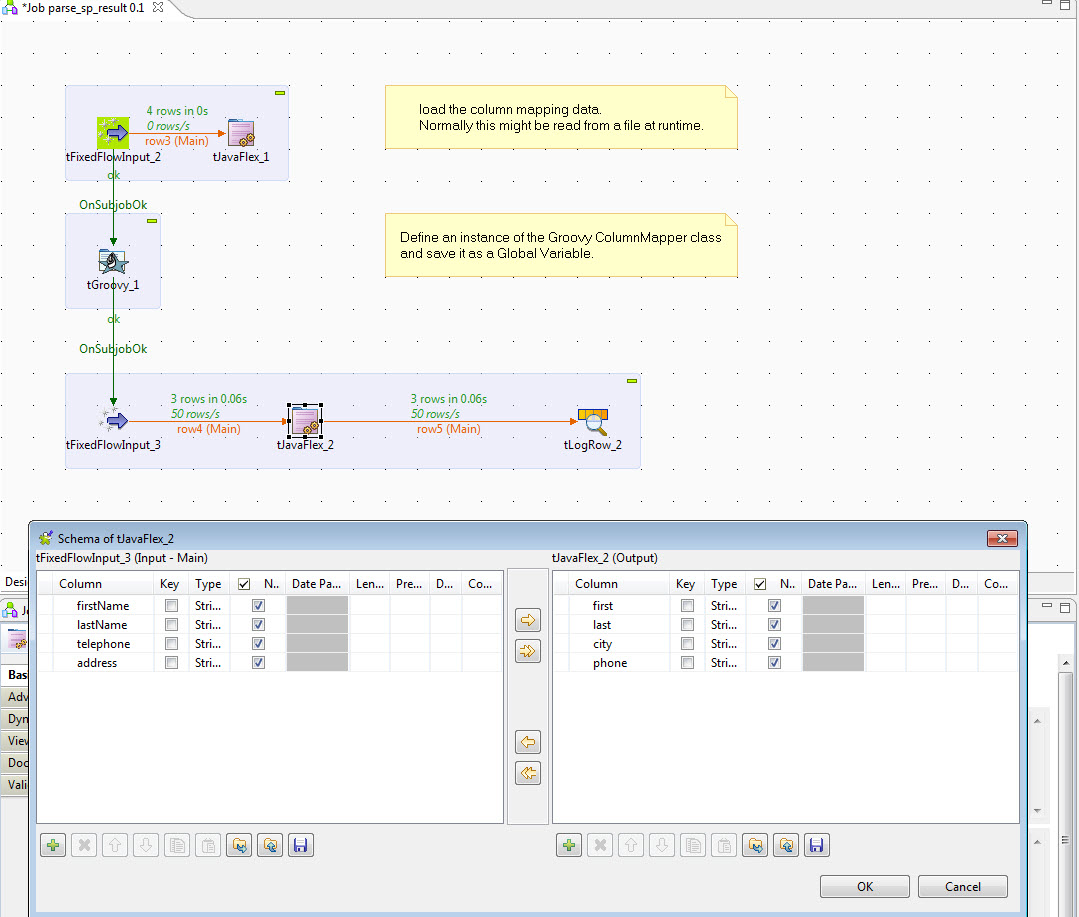
In the example above we have two subjobs that do the setup, followed by a trivial flow that uses our GroovyColumnMapper within a tJavaFlex component. The input and output schemas of the tJavaFlex_2 component are also shown to illustrate that the name and order of fields changes. Note that the although in this example the number of output fields matches the number of input fields, the number of output fields could be a subset of the the input fields.
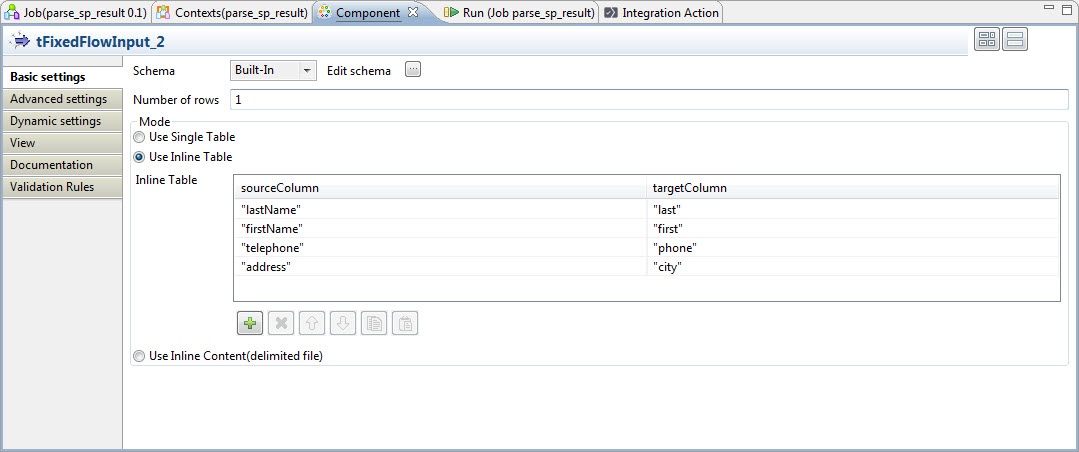
The first subjob uses a tFixedFlowInput to define a Java HashMap which is saved as a global variable. Below is the hardcoded tFixedFlowInput configuration. Normally you might read this configuration mapping from a file, but in the spirit of unit test we are using tFixedFlow here to encode it in the job itself.
The tGroovy component is then used to create a columnMapper. Since Groovy is a dynamic language and has an API for its bean properties we can set up a column mapper that will work for any input and output row data types.
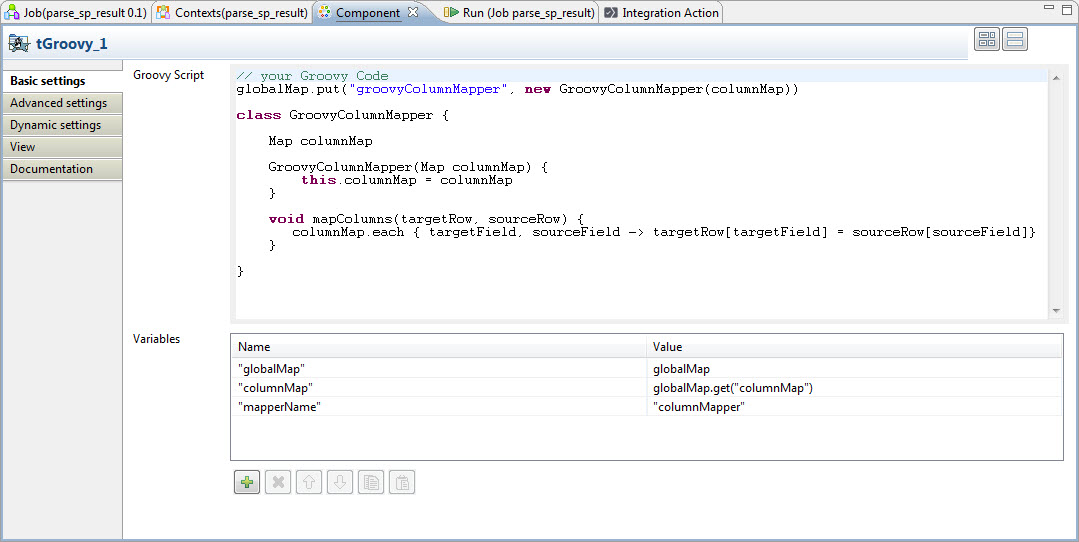
The variables in the screenshot are parameters that are being passed to the Groovy script. We have passed in the globalMap as a parameter of the same name since the Groovy script is going to load the new GroovyColumnMapper instance into the globalMap with the key specified by the mapperName parameter. The GroovyColumnMapper instance itself needs the column map to be fully configured. It gets this from the columnMap populated by the tFixedFlowInput in the previous step.
The GroovyColumnMapper itself is very simple. For each field in a target object, we are going to copy the corresponding field from the source. The syntax columnMap.each is just Groovy syntax for an iterator. Since we are iterating over a map, there are two loop parameters, targetField and sourceField. These correspond to the key, value pairs set up by the tFixedFlowInput. Note that the key here is the targetField and the value is the sourceField. We give the column map the name of the output field we want as the key, and it looks up for us the corresponding sourceField.
Now we are ready to execute the sample data flow. Below is the tJavaFlex component used in the third subjob. It invokes the GroovyColumnMapper instance that we just stored in the global variables. Since this is going to be invoked many times, we use tJavaFlex so that the lookup of global variables is only done once in the start code rather than for each row. We have to use the groovy.lang.GroovyObject API to invoke it, but it is not too difficult. The mapColumns method in our Groovy script takes two arguments, so we have to load an array with the outbound and inbound row definitions. That’s it.
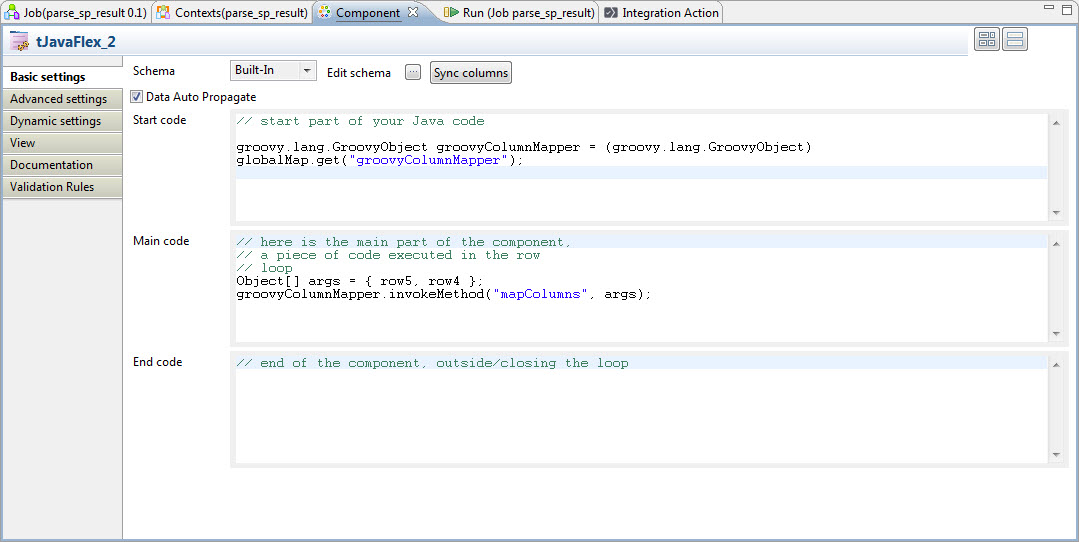
In this example we have given specific names to the input schema prior to transformation. But they could just have easily been generic names such as Column1, Column2, etc. So when we think of this in a production context, the user (or the user’s application) could provide a simple file containing the mapping of generic source to target names. This could be changed for each run of the program if desired, but will typically be a deployment time configuration. No recompile - redeploy needed.