Parameterized Jobs Using Parameterized Jobs for Horizontal Scalability
Overview
Parameterization of Jobs is central to effective re-use and management in an enterprise context which is not only required for running individual jobs, but also for effective orchestration of multiple jobs running on multiple servers in a horizontally scalable environment.
Talend provides a number of different strategies for Parameterization based on Context Variables. These approaches are addressed in the context of re-use with links to the technical details. These approaches are then applied to orchestrating multiple jobs at scale with dynamic control.
Environments
Context parameters are supported on all Talend products. Joblets and TAC are parts of all Enterprise products.
Context Basics
Context Variables
Context Variables are job parameters. For the basic definition see the User’s Guide How to Centralize contexts and variables. The underlying implementation is just Java Properties object.
Context Configurations
A set of Context Variables can be managed as a Configuration. For example, the context variables hostname, ip address, port, and database might be part of a database connection. The database connection might need different values in development, test, and production environments. You can create a separate Context for each environment.
Context Groups
By default Contexts are local to a single job. Create a Context Group if you want to use the same set of Context Variables in multiple jobs. This stores the Context Group definition in the Talend metadata repository so there is a single point of control. You can do an Impact Analysis on a Context Group to identify all Jobs that use the Context Group.
Parameterization Strategies
Embedded Context
By default Context Variables are saved to a flat file which is included in the jar that is generated for the job. Building a Job from the Studio will create a zip file that includes a jar for the generated Job code as well as all jar dependencies, shell scripts for running the job, and properties files for each of the Context Configurations. See How to Build Jobs.
The Context Variables can be overridden at run time using the TAC in the Job Conductor.
tContextLoad and tContextDump
The default embedded Context variables are sufficient for many uses, but if you want programmatic control within your Job of the context you can use tContextLoad and tContextDump. These are just generic input and output components that treat the Context Variables like any other Talend data source. tContextLoad writes a data set to the Context. tContextDump writes the Context to a dataset. The Context dataset schema is always the same, a key and value pair of type String.
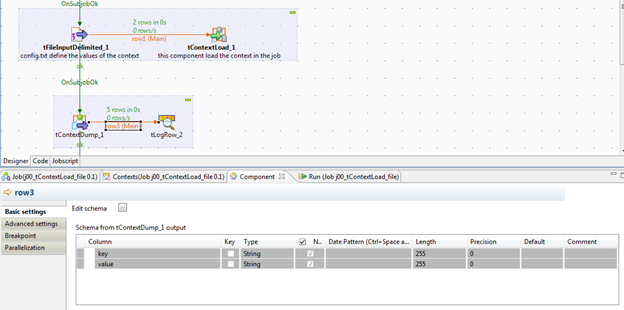
In the example above the Context is loaded from a flat file and then written back out to a tLogRow which displays it on the console. However, it is important to understand that Talend encapsulates data sources so any component could be used to read and populate the Context. It could have been a database or a web service invocation. Conversely, the Context could have been written from the tContextDump to any database or used to invoke a web service which might then log the parameters to a database.
Prejob
When tContextLoad is used to programmatically control job Context variablies, it will typically be invoked prior to the start of the job. Use tPreJob to initiate this segment of the workflow.
Encapsulate Context Management
Using tPreJob and tContextLoad to programmatically control job Context provides a more powerful mechanism for extending job parameterization. But it comes at the cost of potentially invasive copy-paste approaches to job design. Apply good re-use practices to encapsulate Context management in a Joblet which is re-used across all jobs.
Implicit Context Load
Explicit control of Context variables is good, but it is still invasive. It can be made less invasive by using the Implicit Context Load feature. This will automatically load the context from a file or a database. In the screenshot below it is loaded from a database based on a query condition. Note that the query condition itself uses a Context Variable. Since the Job has not yet started this context id must be passed via traditional means via a properties file or via the TAC. But it need contain only a single variable and the rest of the variables will be looked up in the database.
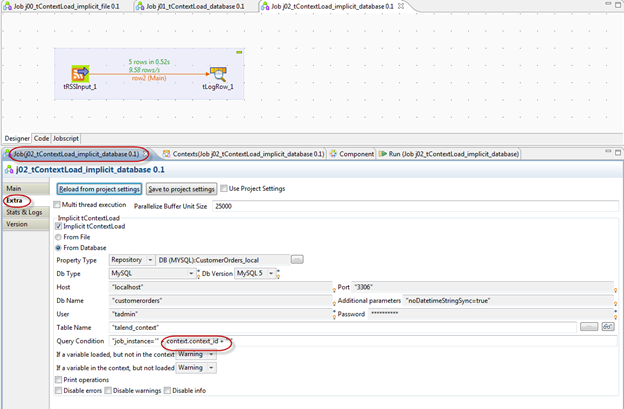
In the example above we are using a user-defined table called talend_context. The only requirement on the table is that it has two fields called key and value. These will be returned in the result set and loaded into the job Context. Other fields can also be part of the table and in this case we have used the job_instance field to scope the query.
CREATE TABLE `talend_context` (
`idtalend_context` int(11) NOT NULL AUTO_INCREMENT,
`project` varchar(45) DEFAULT NULL,
`job` varchar(45) DEFAULT NULL,
`job_instance` varchar(45) DEFAULT NULL,
`customer` varchar(45) DEFAULT NULL,
`key` varchar(45) DEFAULT NULL,
`value` varchar(45) DEFAULT NULL,
PRIMARY KEY (`idtalend_context`),
UNIQUE KEY `talend_context_key` (`project`,`job`,`job_instance`,`key`),
KEY `talend_context_customer` (`customer`)
) ENGINE=InnoDB AUTO_INCREMENT=22 DEFAULT CHARSET=utf8;
Note that in our example the context.context_id field is also a context variable and is coming from the default context properties. If the job itself is triggered through the TAC API (see below) then the context_id can be supplied dynamically by the TAC API client.
Re-use Strategies
Joblet
Joblets are the most granular level of re-use. They allow re-use of functionality across all Jobs within a Project. If re-use is desired across multiple projects place the Joblets in a Reference Project.
Joblets can have their own Context variables independent of the Context variables of the Job. The Context Variable editor will not allow creation of duplicate Context Variables in the parent job once the Joblet has been added. However, if the parent job has been defined with a context variable prior to adding the joblet, then the parent context variable will override the joblet context variable. This of course may or may not be desired behavior.
Joblets should be used to encapsulate Job management infrastructure like the programmatic control of Context Variables for Parameterization.
Note that Joblets can have different types of entry points. This is easy to overlook and can be confusing when first starting off. In the diagram shown below, the Joblet is configured with TriggerInput and TriggerOutput entry points. These are different than the Input and Output entry points. TriggerInput does not transfer any data set. It is just notification that the subjob(s) encapsulated by the joblet can begin. In contrast, Input entry points will receive a data flow based on the declared schema from the parent job.
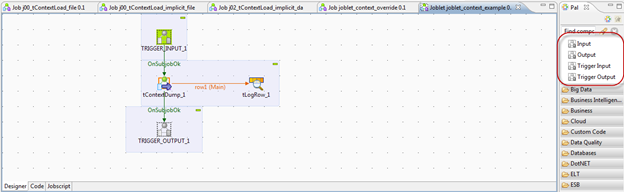
See the Knowledge Base regarding Differences between a Joblet and the tRunJob Component.
Child Jobs
In contrast to Joblets, Child jobs are logically separate jobs that generate their own implementation classes. As such they have their own Context as well as error handling. They are implemented with the tRunJob component.
What is particularly relevant about the Differences between a Joblet and the tRunJob Component article is the example using tRunJob to catch errors and still have the parent job continue processing. When used for establishing an error handling context the “Use an independent process to run subjob” checkbox should be cleared.
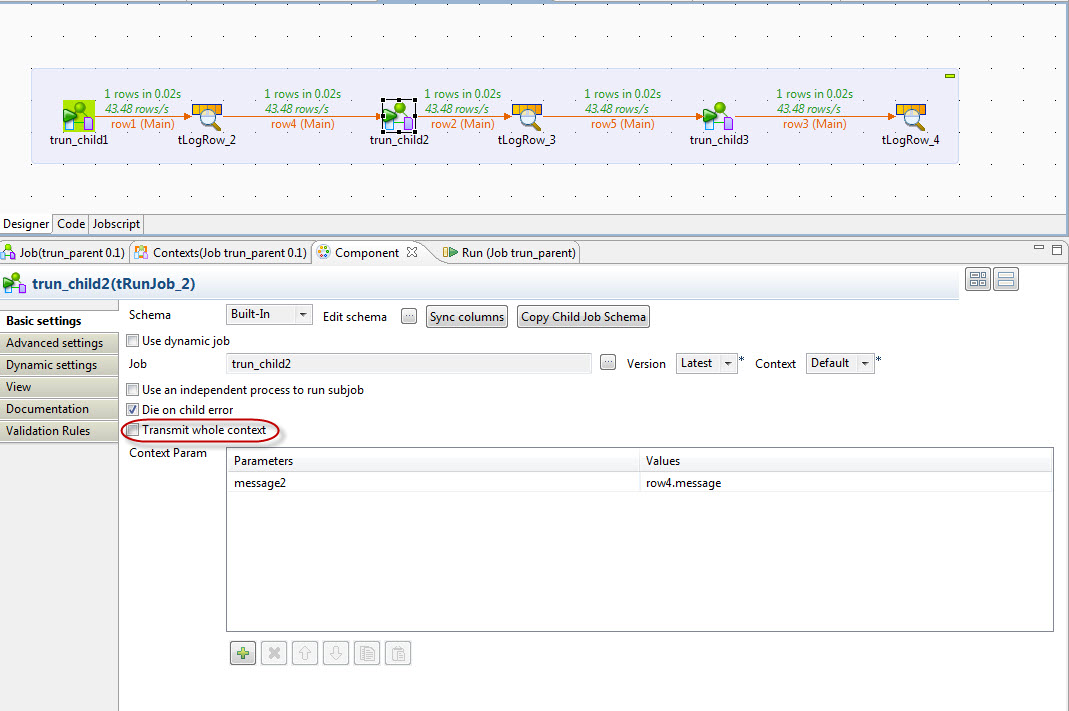
Another important feature of Child Jobs is how they handle context parameters passed from the parent. Child Job context variables are overridden if specified by the parent. In the screenshot below the message2 context variable of the trun_child2 child job will be overridden with the value of output by the previous child job via the row4.message field. So the output of the first child job is setting the context of the second child job.
If there are other context variables in the parent job they can be passed as a group without specifying them independently by checking the “Transmit whole Context” checkbox. This may be more convenient in some cases, but it lacks the clarity of an explicitly defined contract. On the other hand, it may be appropriate if there are extension points driven by the parent’s context.
It should be emphasized that even if the Child job is run in a separate process, it is a separate process on the same machine.
Execution Plans
In contrast to Child Jobs launched with tRunJob, Execution Plans are controlled by admins via TAC in operational environments. If multiple Jobs need to be run either in parallel or in sequence, then this can be done via Execution Plans. Execution Plans reference individual Job entries configured via Job Conductor. Individual Jobs can be scheduled to run via Job Conductor on a specific registered Job Server. When the Execution Plan references multiple Job Conductor entries the resulting jobs may well be running on multiple servers.
In contrast to Child Jobs, jobs run via Execution Plans do not really have a direct means of sharing context variables or of dynamically setting context variables. For example, in the screen shot above the parent job had three child jobs, and the output of the first child job was passed to the context variables of the second child job. Execution plans do not pass any information from the one step to the next. The context parameters must be statically encoded in the Execution Plan itself.
Of course, you could implement conventions within your jobs so that different jobs within the Execution Plan stored their data in a common file or datastore and then use tContextLoad to load the results of the previous step into the current step. The limitation with this approach, however, is that there is no unique Execution Plan instance instance identifier. This makes it impossible for the jobs within the execution plan to reliably communicate without overwriting any previous history. Of course, only one job-conductor instance can be running at a time, but this adds another level of complexity to the framework code. Jobs must save the old context (if desired), load the new context, and then execute.
Execution Plans also have the inherent drawback of having the risk of misconfiguration by the operations team. This is of course both their strength and weakness.
Whereas tRunJob, joblets, and the other options discussed previously are all features in the Talend Studio IDE, the Execution Plan is available via the browser based interface of the TAC.
Dynamic Execution
The Execution Plan allows greater deployment flexibility than parent and child jobs with tRunJob because multiple servers can be used. But it is less flexible than parent jobs because there is limited control of the workflow. An alternative is to use the TAC API from the parent job to trigger child jobs which can run on separate servers.
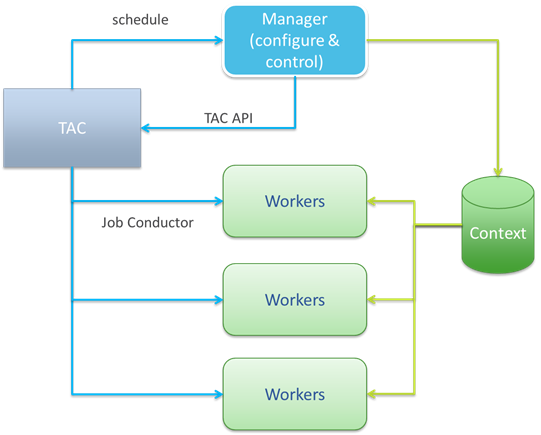
Scaling Jobs Horizontally
Figure 1 below combines the concepts discussed above in a basic design for horizontally scalable jobs with Talend Data Integration. A parent Manager job is shown which orchestrates a number of worker jobs. Worker Jobs may partition a particular task, or they could be run in sequence on distinct steps which might be executed in parallel or in sequence. The Manager job may also configure the parameters used by the Worker jobs by populating the Context parameters in a database. The workers receive the id of their Context Database parameters via the TAC invocation, and then use the Implicit Context Load as shown above to load the rest of the parameters.